A ThoughtPoint by Dr Barry Devlin, 9sight Consulting
June 2019
Sponsored by CortexAG
A German version of this article is available at Informatik Aktuell.
CoxtexDB combines SQL and NoSQL technology to offer business the freedom of highly flexible operations together with the structure needed to manage its fundamentals. In this second of a series of articles, we see how this is the foundation of true data agility and digital business transformation.
ThoughtPoint 2 of a 5-part Series

In the first article of this series, “CortexDB Reinvents the Database”, I suggested that CortexDB was rather more than a database. Rather, I see it as a first example of an adaptive Information Context Management System (ICMS).
From a technology viewpoint, CortexDB uses a combination of SQL and NoSQL to support both the structure and flexibility, the planning and agility that characterise an ICMS. In doing so, it offers business the freedom of completely flexible operations together with the ability to manage its fundamentals.
Like the brain, from which the product derives its name, CortexDB is conceptually simple. The semantic structure of all types of data is preserved in a document store, which is automatically described and modelled in an integrated, relational sixth normal form (6NF), multi-dimensional index that points to every piece of data in every document in the store.
In contrast to a traditional relational database, a document store offers an infinite range of structuring. A classical, simple text document consists of characters arranged in words and sentences. A video or audio file is a binary large object with some metadata fields. An e-mail document consists of a few defined and named fields and their values (key/value pairs), such as Sender and Subject, as well as the body of the e-mail, which is simple text. A field-based document, such as XML or JSON, consists of an arbitrary set of key/value pairs such as FirstName: “John”, DoB: “19451123”, and so on. A document store can contain any of these data types and more.
Obviously, the level of structuring in a document store determines the processing possible. In a simple text document store, we can find and count all occurrences of a word such as “Macintosh”. However, it is only when the document contains defined and named fields that we can distinguish between “Macintosh” as a model of computer, a type of coat, or Scottish last name, and find and count them separately.
Finding and counting (and, indeed, all types of more complex data processing) lead to the need for indexing to speed up access. A simple text document store is processed via an inverted index, which is simply an ordered list of all non-trivial words in the store together with pointers to the documents where they appear and their positions within those documents. In a document store that contains more structured documents, the contents of every individual field can be indexed in a similar manner.
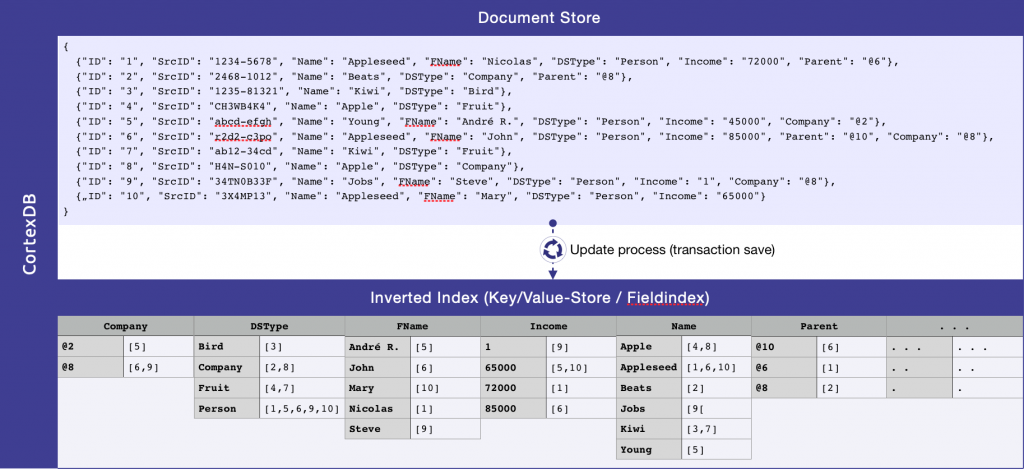
CortexDB provides an inverted index of every value of every field in the data store that allows every instance of “Macintosh” as a last name, for example, to be easily found in the document store. As a result, these indexes can be used to process—count, average, max and min, etc.—data in each field. More interestingly, the complete set of indexes for a document store represents the most discrete level of model (6NF) possible for the fields and contents of the document store. Simple set operations, such as union, intersection and complement, can thus be easily performed. At 6NF level, such set operations map directly to the more familiar language of “select” and “join” in SQL terminology, allowing all the Macintoshes (of any type) in London to be located. Furthermore, this is the correct level of normalisation at which to apply temporal concepts, graph structures, and other fundamental data management approaches. Further details can be found in Thomas Kalippke’s article on Medium.
The consequence of having such a multi-dimensional, 6NF set of indexes may be surprising to data designers who are trained in traditional modelling methods. Because 6NF is the most fundamental and simple representation of data, all other normalization levels can be subsequently built from it. However, in a traditional relational database, the use of 6NF is complex and cumbersome due to the number of joins of very narrow tables required and performs poorly.
CortexDB’s use of 6NF inverted indexes overcomes these issues and supports the full power of the 6NF approach. At design and initial load time of the data store, modelling is reduced to the identification, naming and typing of the individual fields. Any other more complex modelling needed—such as defining dimensional or 3NF structures, creating temporal databases, etc.—can be addressed at a subsequent design stage.
This separation of design-time concerns from run-time concerns is what makes CortexDB a context-aware system and elevates its view from data to information, an adaptive Information Context Management System.
This is also the meaning of true data agility. Any required business use of data can be defined and implemented after the data has been stored, using the initial data set. Given the performance characteristics of the 6NF structure, it is seldom necessary to create further copies of the data in different formats.
For business insight applications, such as business intelligence and analytics, that are at the heart of digital transformation, eliminating—or even significantly reducing—the need for multiple copies of the same data in different structures drives new levels of agility and speed of delivery in IT. Similar considerations apply to the new operational applications required by digital business.
This novel approach to data structure enables new ways of thinking about data, allowing a focus on business needs rather than database constraints, and improving IT productivity as well as time to market for new applications. Such data agility is at the core of digital business.
From Data Agility to Digital Business
Digital business has become the buzzword for what business needs to do as this decade comes to a close. Despite its popularity, its definition is often unclear. In its technical essence, it centres around a change in sourcing of business data, from mainly internally from business processes to largely externally from the real world. Allow me to explain…
Way back in the last millennium, the data needed by business to operate was well-structured, (reasonably) well-governed, and almost entirely sourced from within the walls of the business itself. This is process-mediated data: the legally binding foundation of business, as described in my book Business unIntelligence. Relational databases — highly structured, carefully managed, but resistant to change — ruled the data world. For decision making, data warehousing was king.
However, within the last decade, the data landscape has changed completely. Complexity and data volumes are increasing not only as a result of the automation of processes and the requirement for more agility. Social media, click streams, and the Internet of Things have brought huge volumes of rough and raw data: externally sourced, poorly structured, loosely governed, and varying in structure over time. The focus of today’s digital businesses has turned to insights from this human-sourced information and machine-generated data.
Relational databases fell out of favour, to be replaced by NoSQL data stores of varying forms. Data flooded into lakes, threatening to wash away the dusty, old warehouses. Except it didn’t. Because managing the legal foundation of business, using process-mediated data, is still mandatory.
These conflicting requirements, together with the above explosion of data volumes, demand that IT must now become as agile in data design and management as it has in development. Data created in one environment must be readily used and reused in multiple contexts. This leads us back to the Information Context Management System and its implementation in CortexDB.
Subsequent articles in this series will look at some of the applications of this technology and how CortexDB has been used in support of digital business and in all its various forms.
Links to other articles in the series:
Article 1: CortexDB Reinvents the Database – June 2019
Article 3: Managing Data on Behalf of Different Actors – June 2019
Article 4: Distilling Deeper Truths from Dirty Data – July 2019
Article 5: CortexDB Drives Agile Digital Transformation – July 2019
Leave A Comment